

 资讯
资讯
 portant;" />
portant;" />
前阵子,一位同传翻译员(yuán)声讨科大(dà)讯飞“AI同传(chuán)造假”,在(zài)网上引(yǐn)起了轩然大波。人(rén)工智能和同传翻(fān)译由此成为大家热议的话题。今天,我们来谈一谈(tán)“人(rén)工智(zhì)能翻(fān)译是否真的可以取代(dài)同传(chuán)翻译员(yuán)”?
同声传译有(yǒu)多难?
同声传译最早出现在一战后的巴黎和会(huì)上(shàng),英法两国代表借助(zhù)同声传译人员(yuán)的帮助,完成了紧张的谈判(pàn)。
如今,该技术依然在国际会(huì)议上扮演(yǎn)着极其重要(yào)的角色。据统(tǒng)计,95%的(de)国际会议都有(yǒu)专业同声传译人员助力。
同传翻译(yì)员在台(tái)上能够(gòu)将同传能力运用(yòng)自如(rú),需要平时大量(liàng)的(de)艰苦练习,即使是双语(yǔ)运用自如的专业人员,在实(shí)战之前,也要(yào)进行数(shù)年的锻炼。他们不仅需要事先学习、熟(shú)悉会议(yì)资料,还(hái)需要随机应变的能力。同声传(chuán)译(yì)的工(gōng)作方式也比较特殊(shū),因为压力巨大,一般多人(rén)协同,在一场数小时的过程中,每人轮流翻译几十(shí)分钟(zhōng)。
相较之下,普通的口译工作则要简单不少。机器翻译如(rú)能代替同声传译无(wú)疑具有巨(jù)大的价值(zhí)。
人工智能翻译的(de)水平如何?
那(nà)么(me),人工(gōng)智能同传翻译(yì)的(de)能力究竟怎(zěn)样(yàng)?会不会抢走(zǒu)同(tóng)传翻译员的饭(fàn)碗呢?
今年上半年的(de)博鳌亚洲论(lùn)坛上,首(shǒu)次出(chū)现了AI同(tóng)传。然(rán)而,现场配备的系(xì)统却掉了链子(zǐ),闹出词汇(huì)翻译不准确、重复等低级(jí)错误。
客观来讲(jiǎng),人工智能或机器(qì)翻译技术在自然语言处理上,的确有许多突破。这些突破给人希望,让人(rén)畅(chàng)想未(wèi)来(lái),但是,短期(qī)内的价值,更(gèng)多体现在辅助翻译等领域。
当然,目前机器翻译已经取得非常(cháng)大(dà)的进步,在衣食住行等常用生活(huó)用语上的中英翻译可以达到大学(xué)六级的水(shuǐ)平,能够帮助人(rén)们(men)在(zài)一些场景处理语言交流(liú)的问题,但距离人工同传(chuán)以及高水平翻译所讲究的“信、达、雅”,还存在(zài)很(hěn)大的差距。
目前的差距是由现有技术水平的限制决定的,机(jī)器翻译,又称为自动翻译,是利用(yòng)计算机(jī)将一(yī)种语言转换为另一种语言,机器翻译技术的发展与计算机技术、信息论、语言学等学科的发展(zhǎn)紧密相关。从早期(qī)的词典匹配(pèi),到结合语(yǔ)言学(xué)专(zhuān)家梳理的知(zhī)识规则,再到基(jī)于语料库的(de)统计(jì)学方法,随着计算能力(lì)的提升和多语言(yán)信(xìn)息的积累,机器翻译技术开始在一些(xiē)场景中提供(gòng)便捷的翻译服(fú)务。
新世纪以来,随着互联网的(de)普及(jí),互联网公司(sī)纷纷成立机器翻译研究组(zǔ),研发了基于互联网大数据的机器翻译系统,从而使机器翻(fān)译真正走(zǒu)向实用(yòng),市场上开始出现比较成(chéng)熟的自(zì)动(dòng)翻译(yì)产品。近年来,随着(zhe)深度学习的进展,机(jī)器翻译技(jì)术得到了(le)进一步的发(fā)展,促(cù)进了翻译质量的提升,使得翻译更加地(dì)道、流畅(chàng)。
机器翻译的难点在(zài)哪里?
这里,简单介绍一下机器翻译(yì)的难点。整个机器翻译(yì)的过程(chéng),可以分为(wéi)语音(yīn)识别转换、自(zì)然语言分析、译文转换和译文生成等(děng)阶段。在此(cǐ),以比较典型的、基(jī)于(yú)规则(zé)的机器同传翻译为例(参见下图(tú)),模(mó)块包含了:语音识别(语音转换为文(wén)本)、自然语言(yán)处理(语法分析、语义分析(xī))、译文转换、译文生(shēng)成和语(yǔ)音生成(chéng)等模块。其(qí)中的技术难点(diǎn)主要是(shì):语(yǔ)音识别、自然(rán)语言处理和(hé)译(yì)文(wén)转换(huàn)等(děng)步(bù)骤。
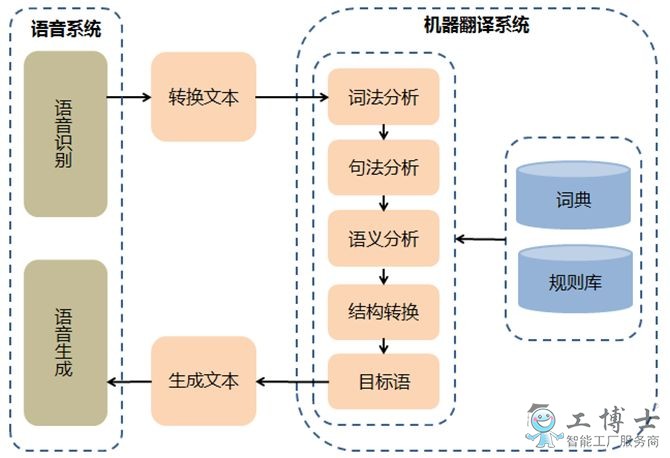
第(dì)一个技术难点是语音识(shí)别。近二十年来,语音识别技术取得了显著进步,开始进入家电(diàn)、汽车、医疗(liáo)、家庭服务等各个领域。常见的应用系统有:
语音输入(rù)系(xì)统(tǒng),相对于(yú)键盘输(shū)入方法,它更符合人(rén)的日常(cháng)习惯,也更自然、更高效;
语音控(kòng)制(zhì)系统,即用语音来(lái)控制设备的(de)运行,相(xiàng)对于(yú)手动控(kòng)制来说(shuō)更(gèng)加快捷(jié)、方便,可以用(yòng)在(zài)诸如(rú)工业控制、语音拨号系统(tǒng)、智能家电(diàn)、声控智能玩具等许多领域;
智能对话(huà)查询系统,根据(jù)客户的语(yǔ)音进行操(cāo)作,为(wéi)用(yòng)户提供自然、友(yǒu)好的数(shù)据库检索服(fú)务,例如(rú)家庭服务、旅行社服务系(xì)统(tǒng)、订票系(xì)统、银行服务等(děng)。
可(kě)以说,语音识别技术与其(qí)他自然语言处理技术相结合,可(kě)以构建(jiàn)出很(hěn)多复(fù)杂的应用。
然而,语音识别(bié)的(de)主要难点就是对自(zì)然语言的识别和(hé)理解。首先(xiān)必(bì)须将连续的讲话分解为词、音素等单位,其次要(yào)建立一个理解语义的规(guī)则。由(yóu)于语音信(xìn)息量大,语音(yīn)模式不(bú)仅对(duì)不(bú)同的说话人不同,对不同场景的(de)同(tóng)一说话人(rén)也是有差(chà)异的(de)。
例如,一个人在随意说话和认真说(shuō)话时的语(yǔ)音特征(zhēng)是不同的(de)。另外,说话者在讲话时,不同(tóng)的词(cí)可(kě)能听起来是相似(sì)的,这也是常见现象。单(dān)个(gè)字母或词(cí)、字的语音特性,受(shòu)上下文(wén)的(de)影响,以致改变了(le)重音、音调、音量和(hé)发音速度等。最后,环境(jìng)噪声和干扰对语(yǔ)音(yīn)识别也(yě)有较(jiào)大影响,致使识别率低。
第二个技术(shù)难(nán)点是语义解析,这是智能化的机器(qì)翻译系统的(de)核(hé)心部分。目前,机器翻译(yì)系(xì)统可划分为(wéi)基于规则和基于语料库两大(dà)类。前(qián)者(zhě)以(yǐ)词典(diǎn)和语言知识(shí)规则库为(wéi)基础;后(hòu)者(zhě)由经(jīng)过划分(fèn)并具有标注的(de)语料库构(gòu)成知识源,以统计学(xué)的算法为主。
机译系统是随着语料库语言学的兴起而发展起来的。目前(qián),世界(jiè)上绝大多数机译(yì)系统都采用以(yǐ)规(guī)则库为(wéi)基础的策(cè)略,一般分为语法(fǎ)型、语义(yì)型、知识型和智能型。不(bú)同类(lèi)型的(de)机译(yì)系统,由不同(tóng)的(de)成(chéng)分构成(chéng)。抽象地说,所(suǒ)有(yǒu)机(jī)译系统的处理过程都包括以(yǐ)下(xià)步骤:对源语言的分(fèn)析或理(lǐ)解(jiě),在语言(yán)的语法、语义和语(yǔ)用等平面进行转换,按目(mù)标(biāo)语(yǔ)言结构规则生成目标语(yǔ)言。
当前,Google 的在线(xiàn)翻译已经(jīng)为人熟知(zhī),其第一代的技(jì)术即为基于(yú)统计的机器翻译方法,基本原理是通过收集大量的双语网页作为语料库,然后(hòu)由计算机自动选取最为常见的词与词的对应关(guān)系(xì),最后给出(chū)翻(fān)译结果。
不(bú)过,采用该技术(shù)目前仍无法达到令人满(mǎn)意(yì)的效果,经(jīng)常闹(nào)出各种(zhǒng)翻译笑话(huà)。因为,基于统计的方法,需要(yào)建立大规(guī)模(mó)的双(shuāng)语语料库,而翻译模型(xíng)、语言模(mó)型参数的准确性直接依赖于语(yǔ)料(liào)的规模及质量,翻译质量直接(jiē)取决于模型的质量(liàng)和语料库的覆盖面。
除了上(shàng)述传统的方式,2013年以来,随着深(shēn)度(dù)学习的研究取得较(jiào)大进展,基于(yú)人工(gōng)神(shén)经网(wǎng)络的机器翻(fān)译逐渐兴起(qǐ)。就当前而言(yán),广(guǎng)泛应用于机器翻译的(de)是(shì)长短时记忆循(xún)环(huán)神经网络。该模型擅(shàn)长对自然语言(yán)建模,把任意长度(dù)的(de)句子转化为特定维度的浮点数向(xiàng)量,同(tóng)时“记住”句子中比较重(chóng)要(yào)的单词,让“记忆(yì)”保存比较长的会话时间。该模型较好地(dì)解决了自然(rán)语言句子向量化的难题。
其技术(shù)核心是通过多层神经网络,自动从(cóng)语料(liào)库中学习(xí)知识。一种(zhǒng)语(yǔ)言的句子被(bèi)向量化(huà)之后(hòu),在(zài)网络中层层传递,经过多(duō)层复杂的传导(dǎo)运算,生成译文。这种翻译方法最大(dà)的优势(shì)在于译(yì)文流畅,更加符(fú)合语法规(guī)范。相比之前的(de)翻译(yì)技术,质量有(yǒu)较高(gāo)的提升。
智能同传翻译离我们还有多远?
需要说明的是,很多人对机器翻译(yì)有误解,认为机器翻译偏(piān)差大。其实,机器翻译运用语言(yán)学知识,自动识别语法,模拟语义理解,进行对应翻译,因语法、语义、语用的复杂性,出(chū)现错误(wù)是难免的。就已有的成果(guǒ)来看,全场景通(tōng)用的机器翻译,其翻译质量离(lí)终极目标仍相(xiàng)差甚远(yuǎn)。
随着全球化网络时(shí)代的到来,语言障碍已经成为二十一世(shì)纪社会(huì)发展的重要瓶颈,实现任意时间、任意地点、任意语言的无障碍自由沟通是人类追求的一(yī)个(gè)梦想。这仅是(shì)全球(qiú)化背(bèi)景下的一个小缩影。在社会(huì)快速发展(zhǎn)的进程中,机器翻译(yì)将扮演越来越重要的角色。










察")

良信息举报中心(xīn)")
